


Ian Sampson
-
Posts
13 -
Joined
-
Last visited
-
Days Won
1
-
Sadly no — the underlying AI/ML engine is very dependent on Apple frameworks & hardware (using Metal for GPU acceleration, etc.) and would need a total rewrite to work on Windows. Maybe one day!
-
Sorry for the slow reply — I really should check this forum more often! Really appreciate the kind words about the plugin. And yes, working on some updates. I’ve got a prototype VST that can run inside RX, so you can take advantage of the spectrogram view there. Hopefully ready sometime this Fall. And experimenting with making another plugin (built on the same engine) to handle mouth clicks & the like. Cool idea! That’s certainly a possibility — the new VST algorithm works in real-time, albeit with high latency, so maybe a live mic feed would work. To compete with Krisp though I’d definitely need a pretty big marketing & support team — right now it’s still just me, and I’m pretty happy for the time being keeping things small and focusing on tools for audio post. We’ll see :)
-
I’m biased of course, but I’ve A/B-ed the two extensively and Hush Pro has significantly fewer artifacts on pretty much all the examples I tested. Of course, it may well depend on the material, so always good to demo with your own samples. Clarity is pretty impressive for a real-time, CPU-based plugin. Hush Pro takes a different approach: it’s mainly an offline processor (with real-time previews supported in AudioSuite), which means it can look at the whole audio file at once and make better use of context. And it runs on the GPU, so it has way more processing power available. Obviously a non-starter if you need a real-time insert, but on sound quality alone it’s tough to beat. Not anytime soon I hope 😛 As far as AI goes, Hush Pro is pretty limited in scope. It can’t make creative decisions (e.g. about how much noise and/or reverb to take out for a particular scene), and isn’t all that different from traditional NR, except that it sounds really transparent. And I haven’t heard/seen a single AI model yet that doesn’t make mistakes sometimes — so I expect we’ll need humans in the loop for a long time yet.
-
It should work pretty well! It’s trained to handle dynamic vocal sounds (so laughter, sobbing, etc.) as well as ordinary speech. And it’s purely subtractive, filtering out unwanted sounds — it doesn’t re-synthesize or re-generate the voice, so low risk of sounding robotic or falling into the uncanny valley. Unfortunately no — at the moment, Hush Pro only works on macOS.
-
Sorry for not replying before! This one slipped through the cracks. But yes, exactly — I take dry recordings and convolve them with impulse responses, then train the model to predict the dry signal from the wet one. Also just released an AudioSuite version of Hush — covered in a new thread.
-
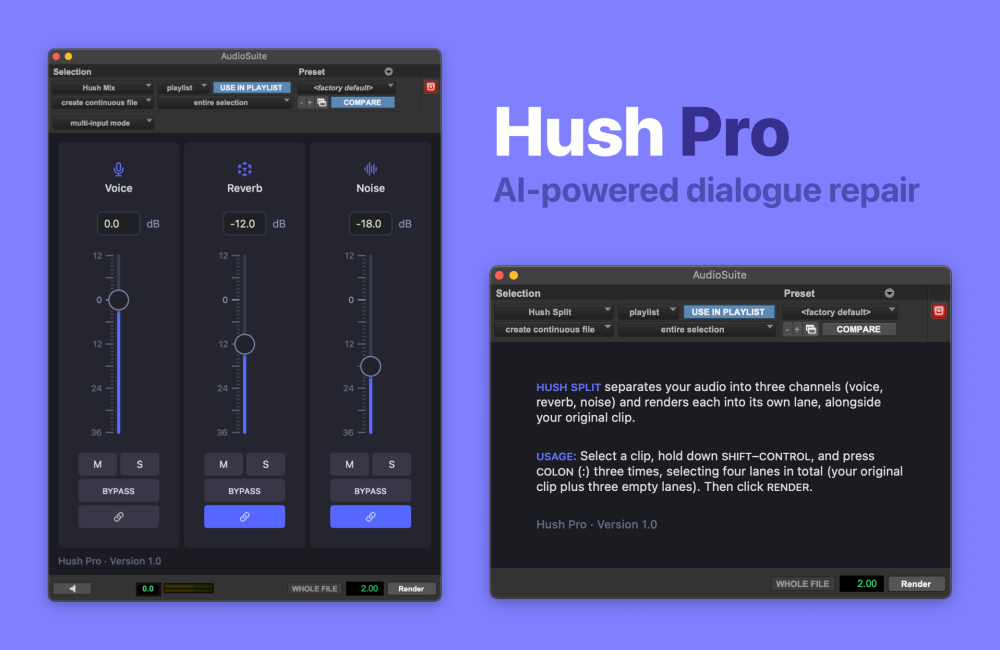
Hi everyone! Back in March I posted about my app Hush, which uses machine learning on Apple Silicon to remove noise and reverb from spoken audio. A lot of folks asked me to make an AudioSuite plugin to speed up the workflow in Pro Tools — so I did. It’s called Hush Pro, and comes with a bunch of new features designed specifically for audio post-production. The plugin includes two separate modes — or sub-plugins — that use the same engine under the hood but support different workflows. Hush Mix lets you rebalance dialogue, noise, and reverb with a mixer-style UI, previewing the results in real time. Hush Split renders all three elements as separate clips for more fine-grained, non-destructive edits. The Pro version delivers even cleaner audio than the standalone Hush app, with better handling of outdoor ambience, highly reflective rooms, overlapping voices, and non-verbal sounds like laughter. Under the hood, the plugin uses a new, more powerful AI model, taking advantage of the faster GPU on M-series Pro, Max, and Ultra chips. The model will continue to evolve with future updates — so if you find a type of voice or noise that it struggles with, let me know and I can very likely improve it. Other plugin formats (AU and VST) are in the works too. They’ll be free updates for Pro users, whenever they’re available. Compatibility Besides Pro Tools, you’ll also need an Apple Silicon Mac and macOS Monterey or Ventura. (Hush Pro doesn’t officially support macOS Sonoma yet, and I recommend against updating until Apple has ironed out a few wrinkles.) Price & Availability Check out the website for more info, a quick video demo, and a 21-day free trial. The full version is $249, or $179 if you’re upgrading from the original app. A one-time purchase includes minor updates and bug fixes (up to version 1.x). No DRM (iLok, license key, etc.): just a simple installer. Both single-user and multi-seat licenses are available. If you have any questions, feel free to post them here or shoot me an email at ian@hushaudioapp.com. Thanks! Ian
-
Haha I just may! I actually have a massive library of insect recordings from another sound design project — if getting rid of cicadas & crickets is desirable I could probably train a model to do that :p.
-
VST and Windows support would be great for sure! At the moment, Hush is pretty heavily optimized for Mac (both at the software level, with CoreML, and at the hardware level, with the Neural Engine). Getting the AI to perform with any reasonable efficiency was only really possible by targeting a specific architecture, and taking advantage of the massive acceleration for machine learning on M1 and M2 Macs. I imagine you could get similar performance on PC using a discrete GPU, but that’d also mean rewriting the app from the ground up. Not impossible, of course! But not likely to happen soon, without help from other developers who know Windows better than I do:p.
-
Sadly, the minimum macOS version is 12.0 (Monterey). If you’re curious to hear what it sounds like on some of your audio, though — and if you have something you don’t mind sharing — I’d be happy to process it and send it back. Yes, AAX would be cool for sure, and going the AudioSuite route would make it easier to get things working without the real-time constraint. Not on the immediate horizon, but I’ll look into it!
-
Thanks for the kind words! That was my goal: to make the model subtle enough that you don’t lose any of the details of the original speech. The processing is designed to kick in only where needed: clean audio passes through unchanged, and moderately noisy audio gets processed pretty gently. (Very loud noise will still produce some artifacts, but hopefully less so than with traditional noise reduction algorithms.) Curious to hear what you think, if you get a chance to try it out :).
-
You’re very welcome! A few podcast editors tried out the beta over the last couple months, and they said it worked really well. It’s trained to handle common types of indoor noise (HVAC, fans, etc.) as well as room reflections, which are probably the main culprits in home podcasting setups. If the noise and reverb are moderate (e.g. using a mic in cardioid at a reasonable distance from the source), the reduction is typically really subtle, without any audible artifacts. That said, it’d probably struggle with audio recorded on, say, a cellphone, or with a laptop mic far away (which can happen, I suppose, with some remote podcast interviews). I don’t do podcasts myself, but I record voiceover and audiobook narration at home, and the app has been super useful in getting rid of all the room tone.
-
Great question — it’s really helpful for me to hear how this might fit (or not fit) into existing workflows. And yes, I’d like to make it into a real-time plugin in the near future. I already have it working as a prototype AU plugin in Logic, but with really high latency (~500 ms) and you can only run one instance at a time without freezing tracks (at least on a base model M1 Mac Mini). A possible solution would be to make a lightweight version of the AI model, which could run more efficiently in real-time, and then switch to the full, high-quality version when you bounce. Trying to prioritize whether to work on the plugin next, or add a spectrogram-based editing interface for offline work with individual clips. Eventually I’d like to do both, but I have to start somewhere, and the plugin may well turn out to be the more useful path.
-
Hi everyone! Just wanted to share an app I made that post-production folks might find useful. It’s called Hush, and it uses AI to automatically remove background noise and reverb from dialogue (and other spoken audio) — with minimal artifacts. I designed the model myself, and trained it on a large dataset of common noise types: ventilation, traffic, honking horns, barking dogs, chirping birds, etc. — as well as room reflections from a wide variety of indoor spaces. You can hear a quick demo over on the website. The model continues to evolve as I add more samples to the training data. I’m always open to suggestions, and happy to fine-tune it for specific use cases wherever possible. For example, I have another module in the pipeline to handle lav-related noise: clothing rustle, muffled dialogue, etc. The app itself is a batch processor with a simple drag-and-drop interface. It can handle single files or many at a time. On Apple Silicon Macs (highly recommended, if not strictly required), it runs entirely on the Neural Engine, which massively accelerates processing while leaving the CPU cool (and the fans off). It can also run on an external GPU. It’s been in beta for two months, and I’ve gotten some great feedback from dialogue editors, voice actors, and other folks who’ve used it in their projects. I just released the first public version on the Mac App Store today, for an introductory price of $49.99 US. You can also download a 21-day free trial, without any other restrictions, at hushaudioapp.com. As a solo developer, I put a lot of care into my work and really thrive on feedback — so if you have any questions or suggestions, please let me know :). Thanks, Ian

